
View all detail and faqs for the Databricks-Certified-Professional-Data-Engineer exam
Which statement describes integration testing?
The data engineering team maintains the following code:

Assuming that this code produces logically correct results and the data in the source table has been de-duplicated and validated, which statement describes what will occur when this code is executed?
A CHECK constraint has been successfully added to the Delta table named activity_details using the following logic:
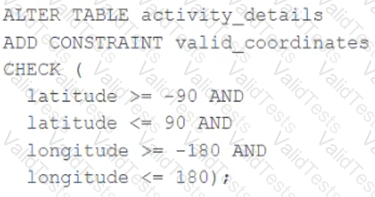
A batch job is attempting to insert new records to the table, including a record where latitude = 45.50 and longitude = 212.67.
Which statement describes the outcome of this batch insert?
What is a method of installing a Python package scoped at the notebook level to all nodes in the currently active cluster?
The data science team has created and logged a production model using MLflow. The following code correctly imports and applies the production model to output the predictions as a new DataFrame named preds with the schema "customer_id LONG, predictions DOUBLE, date DATE".
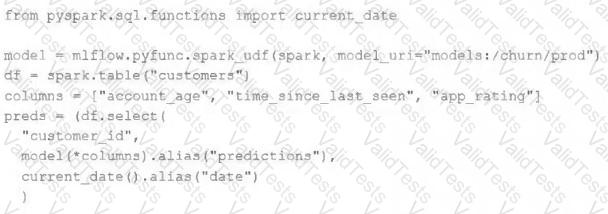
The data science team would like predictions saved to a Delta Lake table with the ability to compare all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
preds.write.mode("append").saveAsTable("churn_preds")
preds.write.format("delta").save("/preds/churn_preds")
C)

D)

E)

Option A
Option B
Option C
Option D
Option E
Which statement characterizes the general programming model used by Spark Structured Streaming?
A team of data engineer are adding tables to a DLT pipeline that contain repetitive expectations for many of the same data quality checks.
One member of the team suggests reusing these data quality rules across all tables defined for this pipeline.
What approach would allow them to do this?
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
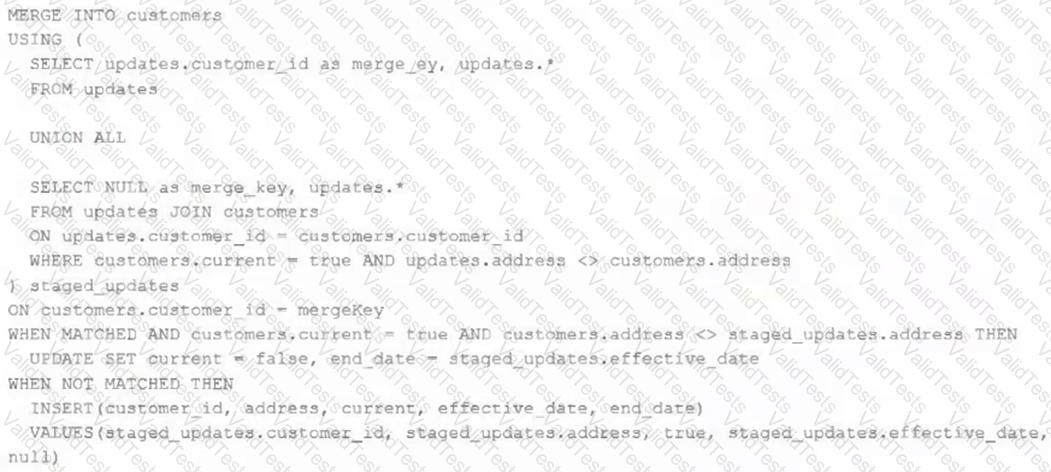
Which statement describes this implementation?
A developer has successfully configured credential for Databricks Repos and cloned a remote Git repository. Hey don not have privileges to make changes to the main branch, which is the only branch currently visible in their workspace.
Use Response to pull changes from the remote Git repository commit and push changes to a branch that appeared as a changes were pulled.
Which is a key benefit of an end-to-end test?