You have a customer complaining of long build times from their NetApp ONTAP-based datastores. They provided you packet traces from the controller and client. Analysis of these traces shows an average service response time of 1 ms. QoS output confirms the same. The client traces are reporting an average of 15 ms in the same time period.
In this situation, what would be your next step?
A customer wants to connect a NetApp AFF A700 system to a 40GbE switch. The controllers have a 10/40G Ethernet card in slot 4 for this purpose. The link comes up fine on node 2, but it will not come up on node 1. You look at the AutoSupport data for the nodes in question and see the output shown in the exhibit.
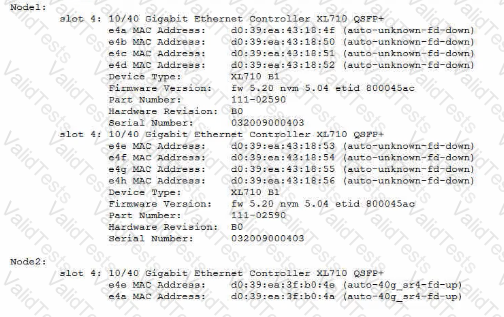
What is the cause of the customer's problem?
Your customer added a new DS4246 shelf to their FAS2750 single-node system and created a new aggregate on the new shelf. Two weeks later, they log into Active IQ and discover the Medium Impact error shown below.
Shelves with both connections via the same SAS path detected
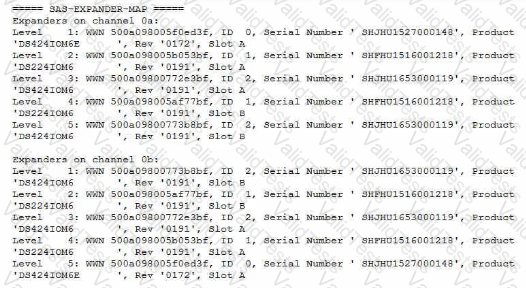
Referring to the exhibit, which statement is correct?
Your customer complains that u host will constantly report losing a connection to the iSCSl target and then report that the session was reestablished.
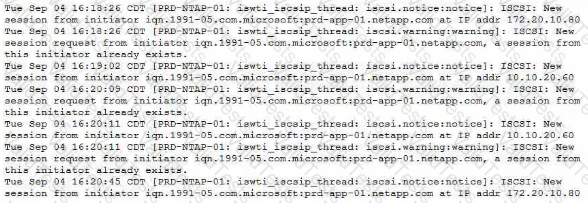
As shown in the exhibit, what is a cause of this flapping?
Your customer Informs you about SnapMlrror problems after upgrading NetApp ONTAP software to a newer version. After investigating the event logs and the SnapMirror history, you see information about delayed updates of the SnapMirror relationships.
How would your customer prevent such problems in the future?
Your customer noticed in NetApp Active IQ that their NetApp Cloud Volumes ONTAP for Azure HA solution is no longer sending AutoSupport messages over HTTPS. A support ticket has been opened to find out why. No changes have been made to the Cloud Volumes ONTAP for Azure HA environment.
In this scenario, which two autosupport command parameters should be used to validate that AutoSupport Is working properly? {Choose two.)
You receive the "Unable to connect to the management gateway server" error when trying to connect to a node management IP.
In this situation, how do you determine whether core dumps are generated for the mgwd user space process?
A customer with an FC MetroCluster configuration that is running NetApp ONTAP 9.8 software experienced a site outage and wants to know why the MetroClusler configuration did not switch over to the other site.
What are two reasons for this problem? (Choose two.)
