
View all detail and faqs for the Workday-Pro-Integrations exam
How does an XSLT processor identify the specific nodes in an XML document to which a particular transformation rule should be applied?
Refer to the following scenario to answer the question below.
You have been asked to build an integration using the Core Connector: Worker template and should leverage the Data Initialization Service (DIS). The integration will be used to export a full file (no change detection) for employees only and will include personal data. The vendor receiving the file requires marital status values to be sent using a list of codes that they have provided instead of the text values that Workday uses internally and if a text value in Workday does not align with the vendors list of codes the integration should report "OTHER".
What configuration is required to output the list of codes required from by the vendor instead of Workday's values in this integration?
What task is needed to build a sequence generator for an EIB integration?
Refer to the scenario. You are configuring a Core Connector: Worker integration with the Data Initialization Service (DIS) enabled, scheduled to run once daily. The integration must extract only active worker records with changes to compensation, home address, or business title since the last 24 hours. It uses Workday’s change detection to avoid full extracts.
During testing, the Core Connector: Worker DIS output unexpectedly includes terminated workers, even though the change detection date parameters are correctly defined for a Full-Diff extract. The requirements specify that only active workers should be included in the output.
What configuration step should you modify to ensure the integration excludes terminated workers?
You are creating an outbound connector using the Core Connector: Job Postings template. The vendor has provided the following specification for worker subtype values:
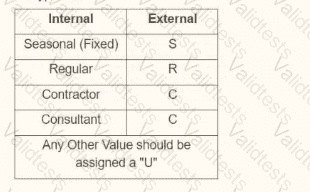
The vendor has also requested that any output file have the following format "CC_Job_Postings_dd-mm-yy_#.xml". Where the dd is the current day at runtime, mm is the current month at runtime, yy is the last two digits of the current year at runtime, and # is the current value of the sequencer at runtime. What configuration step(s) must you complete to meet the vender requirements?
Refer to the following scenario to answer the question below.
You have been asked to build an integration using the Core Connector: Worker template and should leverage the Data Initialization Service (DIS). The integration will be used to export a full file (no change detection) for employees only and will include personal data.
What configuration is required to ensure that when outputting phone number only the home phone number is included in the output?
Refer to the following XML to answer the question below.

You are an integration developer and need to write XSLT to transform the output of an EIB which is using a web service enabled report to output worker data along with their dependents. You currently have a template which matches on wd:Dependents_Group to iterate over each dependent. Within the template which matches on wd:Dependents_Group you would like to output a relationship code by using an
What XSLT syntax would be used to output SP when the dependent relationship is spouse, output CH when the dependent relationship is child, otherwise output OTHER?

B. 
C. 
D. 
Refer to the following scenario to answer the question below.
You have configured a Core Connector: Worker integration, which utilizes the following basic configuration:
• Integration field attributes are configured to output the Position Title and Business Title fields from the Position Data section.
• Integration Population Eligibility uses the field Is Manager which returns true if the worker holds a manager role.
• Transaction Log service has been configured to Subscribe to specific Transaction Types: Position Edit Event. You launch your integration with the following date launch parameters (Date format of MM/DD/YYYY):
• As of Entry Moment: 05/25/2024 12:00:00 AM
• Effective Date: 05/25/2024
• Last Successful As of Entry Moment: 05/23/2024 12:00:00 AM
• Last Successful Effective Date: 05/23/2024
To test your integration you made a change to a worker named Jared Ellis who is assigned to the manager role for the IT Help Desk department. You perform an Edit Position on Jared and update the Job Profile of the position to a new value. Jared Ellis' worker history shows the Edit Position Event as being successfully completed with an effective date of 05/24/2024 and an Entry Moment of 05/24/2024 07:58:53 AM however Jared Ellis does not show up in your output.
What configuration element would have to be modified for the integration to include Jared Ellis in the output?
The following XML code was generated through a RaaS that will be used in an EIB.


Within a template that matches on wd:Report_Entry, what XPath expression do you use to select the value of the Relationship_ID element?
You are creating an outbound connector using the Core Connector: Organization Outbound template. The vendor has provided the following requirements for how the data should appear in the output file.

The vendor would also like to change the default document retention policy of 30 days to 7 days. What tasks do you need to use to configure this in your connector?