
View all detail and faqs for the Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 exam
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
Given a CSV file with the content:

And the following code:
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
spark.read.schema(schema).csv(path).collect()
What is the resulting output?
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
A data analyst builds a Spark application to analyze finance data and performs the following operations:filter,select,groupBy, andcoalesce.
Which operation results in a shuffle?
Which command overwrites an existing JSON file when writing a DataFrame?
What is a feature of Spark Connect?
Given the code fragment:
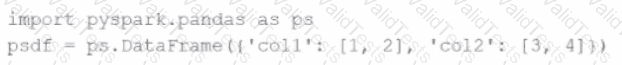
import pyspark.pandas as ps
psdf = ps.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
Given:
python
CopyEdit
spark.sparkContext.setLogLevel("
Which set contains the suitable configuration settings for Spark driver LOG_LEVELs?
Given the code:

df = spark.read.csv("large_dataset.csv")
filtered_df = df.filter(col("error_column").contains("error"))
mapped_df = filtered_df.select(split(col("timestamp")," ").getItem(0).alias("date"), lit(1).alias("count"))
reduced_df = mapped_df.groupBy("date").sum("count")
reduced_df.count()
reduced_df.show()
At which point will Spark actually begin processing the data?
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options: