
View all detail and faqs for the Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 exam
A data engineer wants to create a Streaming DataFrame that reads from a Kafka topic called feed.

Which code fragment should be inserted in line 5 to meet the requirement?
Code context:
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.[LINE 5] \
.load()
Options:
A data engineer writes the following code to join two DataFrames df1 and df2:
df1 = spark.read.csv("sales_data.csv") # ~10 GB
df2 = spark.read.csv("product_data.csv") # ~8 MB
result = df1.join(df2, df1.product_id == df2.product_id)

Which join strategy will Spark use?
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
45 of 55.
Which feature of Spark Connect should be considered when designing an application that plans to enable remote interaction with a Spark cluster?
10 of 55.
What is the benefit of using Pandas API on Spark for data transformations?
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0. The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?

A)
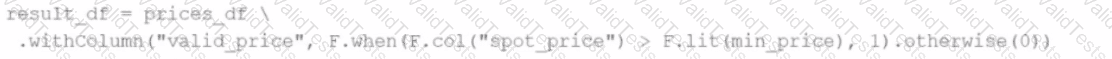
B)
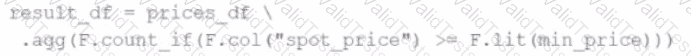
C)
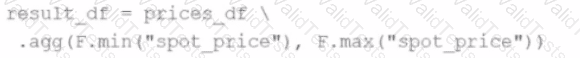
D)

What is the difference between df.cache() and df.persist() in Spark DataFrame?
The following code fragment results in an error:
@F.udf(T.IntegerType())
def simple_udf(t: str) -> str:
return answer * 3.14159
Which code fragment should be used instead?
26 of 55.
A data scientist at an e-commerce company is working with user data obtained from its subscriber database and has stored the data in a DataFrame df_user.
Before further processing, the data scientist wants to create another DataFrame df_user_non_pii and store only the non-PII columns.
The PII columns in df_user are name, email, and birthdate.
Which code snippet can be used to meet this requirement?
A data engineer needs to write a DataFrame df to a Parquet file, partitioned by the column country, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?