
View all detail and faqs for the Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 exam
A Data Analyst is working on the DataFramesensor_df, which contains two columns:
Which code fragment returns a DataFrame that splits therecordcolumn into separate columns and has one array item per row?
A)

B)

C)

D)
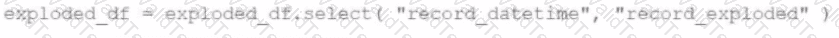
A data scientist is working on a large dataset in Apache Spark using PySpark. The data scientist has a DataFramedfwith columnsuser_id,product_id, andpurchase_amountand needs to perform some operations on this data efficiently.
Which sequence of operations results in transformations that require a shuffle followed by transformations that do not?
A data engineer is building an Apache Spark™ Structured Streaming application to process a stream of JSON events in real time. The engineer wants the application to be fault-tolerant and resume processing from the last successfully processed record in case of a failure. To achieve this, the data engineer decides to implement checkpoints.
Which code snippet should the data engineer use?
Which Spark configuration controls the number of tasks that can run in parallel on the executor?
Options:
A Spark DataFramedfis cached using theMEMORY_AND_DISKstorage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)

C)

D)

Which code fragment should be inserted to meet the requirement?
A Spark application developer wants to identify which operations cause shuffling, leading to a new stage in the Spark execution plan.
Which operation results in a shuffle and a new stage?
What is the difference betweendf.cache()anddf.persist()in Spark DataFrame?
A data analyst wants to add a column date derived from a timestamp column.
Options:
What is the benefit of Adaptive Query Execution (AQE)?