When using the copy into <title> command with the CSV file format, how does the match_by_column_name parameter behave?
Based on the Snowflake object hierarchy, what securable objects belong directly to a Snowflake account? (Select THREE).
What is a valid object hierarchy when building a Snowflake environment?
What is the MOST efficient way to design an environment where data retention is not considered critical, and customization needs are to be kept to a minimum?
When using the COPY INTO
command with the CSV file format, how does the MATCH_BY_COLUMN_NAME parameter behave?
An Architect is designing a solution that will be used to process changed records in an orders table. Newly-inserted orders must be loaded into the f_orders fact table, which will aggregate all the orders by multiple dimensions (time, region, channel, etc.). Existing orders can be updated by the sales department within 30 days after the order creation. In case of an order update, the solution must perform two actions:
1. Update the order in the f_0RDERS fact table.
2. Load the changed order data into the special table ORDER _REPAIRS.
This table is used by the Accounting department once a month. If the order has been changed, the Accounting team needs to know the latest details and perform the necessary actions based on the data in the order_repairs table.
What data processing logic design will be the MOST performant?
What integration object should be used to place restrictions on where data may be exported?
Two queries are run on the customer_address table:
create or replace TABLE CUSTOMER_ADDRESS ( CA_ADDRESS_SK NUMBER(38,0), CA_ADDRESS_ID VARCHAR(16), CA_STREET_NUMBER VARCHAR(IO) CA_STREET_NAME VARCHAR(60), CA_STREET_TYPE VARCHAR(15), CA_SUITE_NUMBER VARCHAR(10), CA_CITY VARCHAR(60), CA_COUNTY
VARCHAR(30), CA_STATE VARCHAR(2), CA_ZIP VARCHAR(10), CA_COUNTRY VARCHAR(20), CA_GMT_OFFSET NUMBER(5,2), CA_LOCATION_TYPE
VARCHAR(20) );
ALTER TABLE DEMO_DB.DEMO_SCH.CUSTOMER_ADDRESS ADD SEARCH OPTIMIZATION ON SUBSTRING(CA_ADDRESS_ID);
Which queries will benefit from the use of the search optimization service? (Select TWO).
The following DDL command was used to create a task based on a stream:

Assuming MY_WH is set to auto_suspend – 60 and used exclusively for this task, which statement is true?
A table contains five columns and it has millions of records. The cardinality distribution of the columns is shown below:
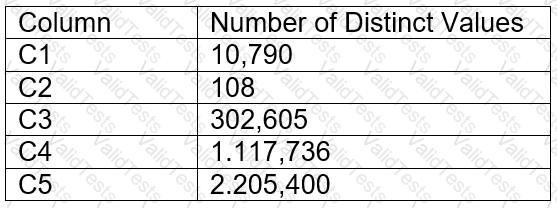
Column C4 and C5 are mostly used by SELECT queries in the GROUP BY and ORDER BY clauses. Whereas columns C1, C2 and C3 are heavily used in filter and join conditions of SELECT queries.
The Architect must design a clustering key for this table to improve the query performance.
Based on Snowflake recommendations, how should the clustering key columns be ordered while defining the multi-column clustering key?
