What is the order of steps for automatically retraining and deploying a Document Understanding ML Model in Al Center with data from Document Validation Action?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.

Which Source Control Plugins can be connected at the same time?
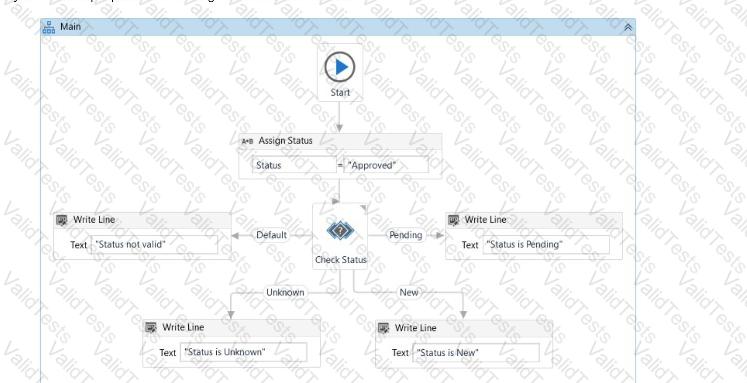
What will be displayed in the Output panel after running the workflow below?
Can a custom-built extractor be used in the Data Extraction Scope activity?
To determine the number of characters scraped from a website in an "ExtractedText" String variable, excluding leading and trailing white-space characters, what should a developer use?
Which of the following extractors can be used for Data Extraction Scope activity?
When processing a document type that comes in a high variety of layouts, what is the recommended data extraction methodology?
Why might labels have bias warnings in UiPath Communications Mining, even with 100% precision?
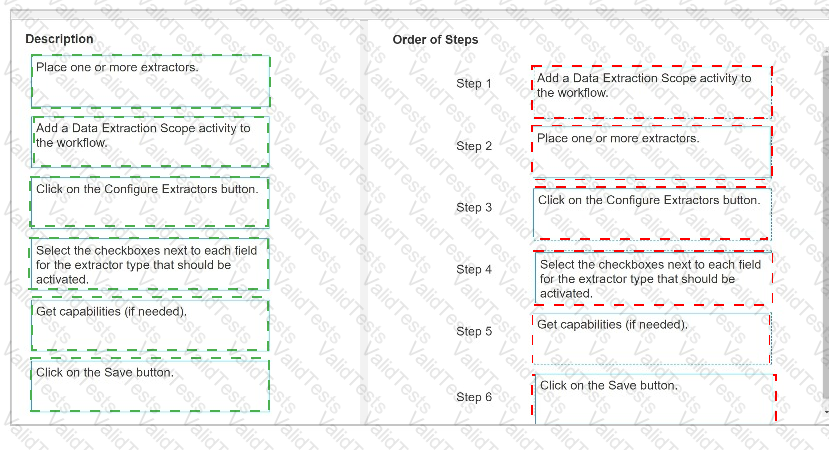
What is the correct order to Configure Extractor Wizard?
Instructions: Drag the Description found on the left and drop on the correct Step found on the right.
Why is it important to understand the potential value UiPath Communications Mining can enable prior to training?


 A screenshot of a computer
AI-generated content may be incorrect.
A screenshot of a computer
AI-generated content may be incorrect.