A company uses an Amazon SageMaker AI model for real-time inference with auto scaling enabled. During peak usage, new instances launch before existing instances are fully ready, causing inefficiencies and delays.
Which solution will optimize the scaling process without affecting response times?
An ML engineer is building a logistic regression model to predict customer churn for subscription services. The dataset contains two string variables: location and job_seniority_level.
The location variable has 3 distinct values, and the job_seniority_level variable has over 10 distinct values.
The ML engineer must perform preprocessing on the variables.
Which solution will meet this requirement?
An ML engineer has trained a neural network by using stochastic gradient descent (SGD). The neural network performs poorly on the test set. The values for training loss and validation loss remain high and show an oscillating pattern. The values decrease for a few epochs and then increase for a few epochs before repeating the same cycle.
What should the ML engineer do to improve the training process?
A company is uploading thousands of PDF policy documents into Amazon S3 and Amazon Bedrock Knowledge Bases. Each document contains structured sections. Users often search for a small section but need the full section context. The company wants accurate section-level search with automatic context retrieval and minimal custom coding.
Which chunking strategy meets these requirements?
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST development effort?
A company wants to use large language models (LLMs) supported by Amazon Bedrock to develop a chat interface for internal technical documentation.
The documentation consists of dozens of text files totaling several megabytes and is updated frequently.
Which solution will meet these requirements MOST cost-effectively?
A digital media entertainment company needs real-time video content moderation to ensure compliance during live streaming events.
Which solution will meet these requirements with the LEAST operational overhead?
A construction company is using Amazon SageMaker AI to train specialized custom object detection models to identify road damage. The company uses images from multiple cameras. The images are stored as JPEG objects in an Amazon S3 bucket.
The images need to be pre-processed by using computationally intensive computer vision techniques before the images can be used in the training job. The company needs to optimize data loading and pre-processing in the training job. The solution cannot affect model performance or increase compute or storage resources.
Which solution will meet these requirements?
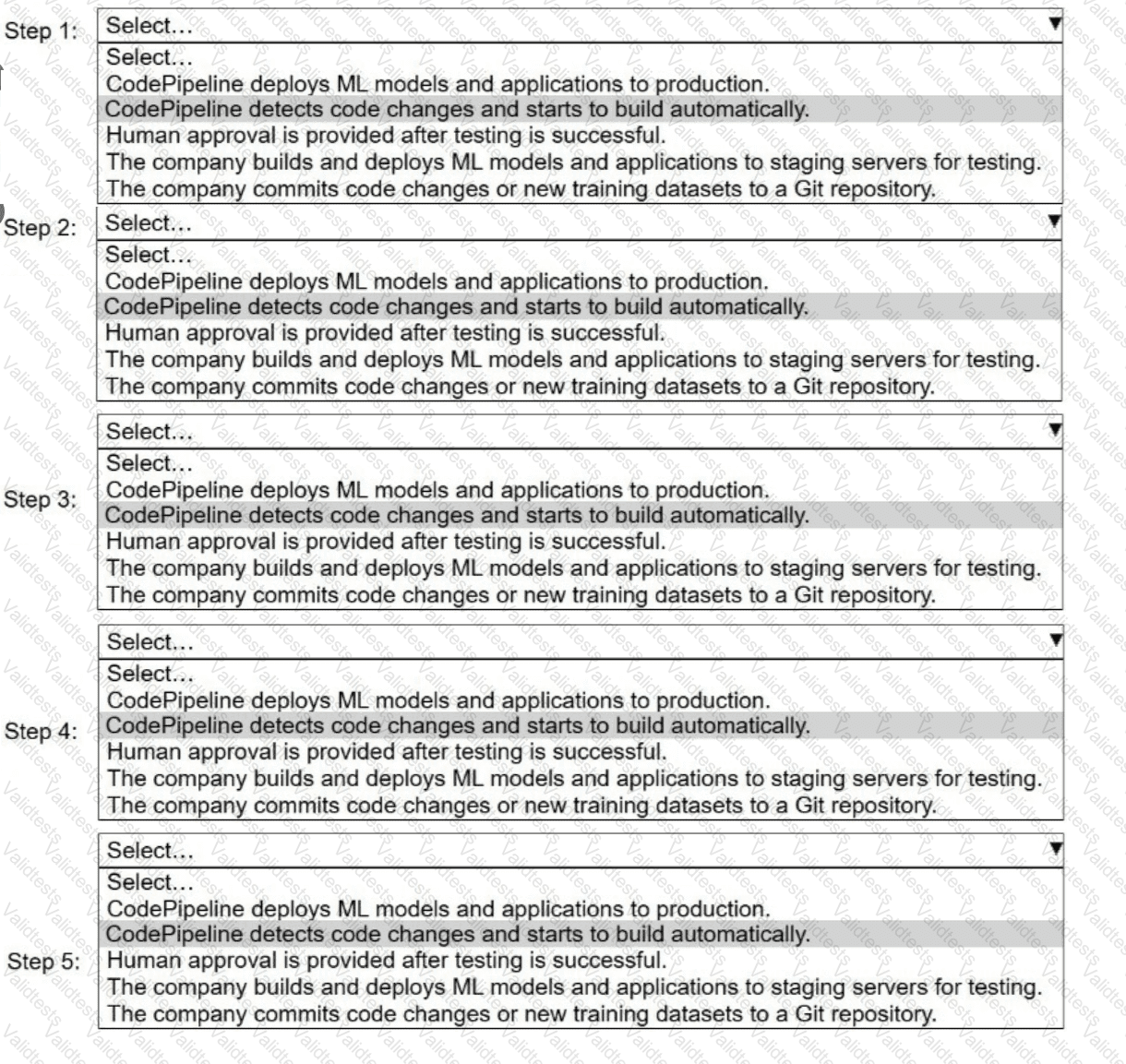
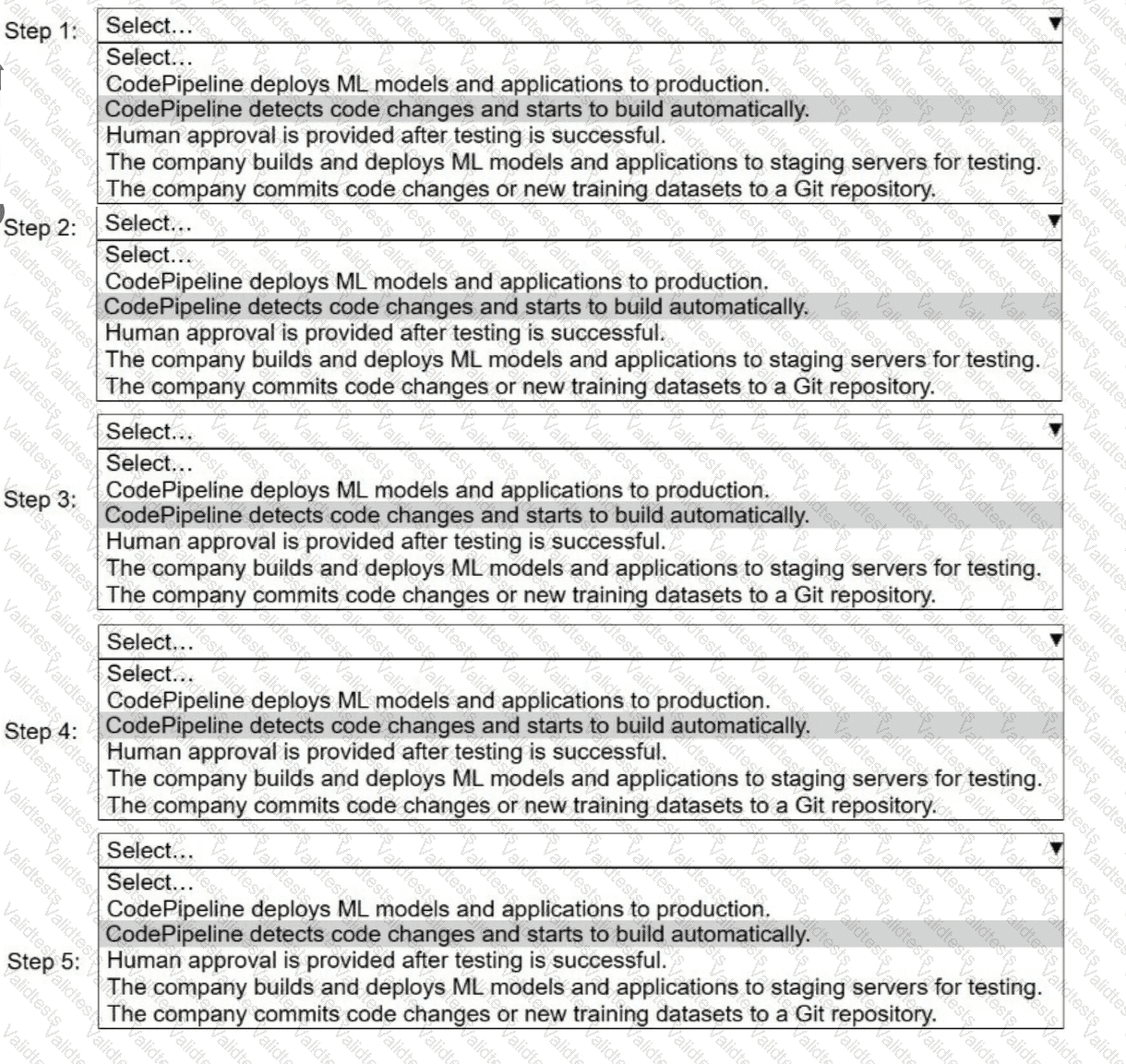
A company uses AWS CodePipeline to orchestrate a continuous integration and continuous delivery (CI/CD) pipeline for ML models and applications.
Select and order the steps from the following list to describe a CI/CD process for a successful deployment. Select each step one time. (Select and order FIVE.)
. CodePipeline deploys ML models and applications to production.
· CodePipeline detects code changes and starts to build automatically.
. Human approval is provided after testing is successful.
. The company builds and deploys ML models and applications to staging servers for testing.
. The company commits code changes or new training datasets to a Git repository.
An ML engineer is developing a fraud detection model by using the Amazon SageMaker XGBoost algorithm. The model classifies transactions as either fraudulent or legitimate.
During testing, the model excels at identifying fraud in the training dataset. However, the model is inefficient at identifying fraud in new and unseen transactions.
What should the ML engineer do to improve the fraud detection for new transactions?